ASINA’s data shepherd concept
Based on: Furxhi et al., 2021
© 2021 by the authors. Licensee MDPI
 Researchers who are unfamiliar with the concept of data management can find it difficult to operationalize the criteria and convey the requirements to others. Despite its significance, metadata capturing, for example, is not widely implemented in everyday academic scientific practice. This is due to the lack of data management training and the general understanding of data management as something that occurs at the end of a project, after data are thoroughly analyzed and published (Papadiamantis et al., 2020). While excellent resources for FAIR realization exist (see FAIRification section), they lack explanations for the initiation process of data collection among partners. The newly defined role of data shepherd (Papadiamantis et al., 2020) was created to help here by supervising the lifecycle of the data rising from multidisciplinary fields, from their generation to capturing and FAIRification. The shepherd considers the needs of different users such as data creators (experimentalists who design and generate new data) and data analysts (the person who performs manipulation and analysis using computational tools) and combines the knowledge and insights in order to communicate requirements between the parties. In other words, the shepherd is strongly engaged and acts as a mediator of information flow between stakeholders by assembling experimental, computational and technical backgrounds. In addition to the communication aspect, the shepherd also leads the FAIRification process and is involved at a technical level (development of templates, annotation and curation), while spreading the awareness of the value of FAIR data.
Researchers who are unfamiliar with the concept of data management can find it difficult to operationalize the criteria and convey the requirements to others. Despite its significance, metadata capturing, for example, is not widely implemented in everyday academic scientific practice. This is due to the lack of data management training and the general understanding of data management as something that occurs at the end of a project, after data are thoroughly analyzed and published (Papadiamantis et al., 2020). While excellent resources for FAIR realization exist (see FAIRification section), they lack explanations for the initiation process of data collection among partners. The newly defined role of data shepherd (Papadiamantis et al., 2020) was created to help here by supervising the lifecycle of the data rising from multidisciplinary fields, from their generation to capturing and FAIRification. The shepherd considers the needs of different users such as data creators (experimentalists who design and generate new data) and data analysts (the person who performs manipulation and analysis using computational tools) and combines the knowledge and insights in order to communicate requirements between the parties. In other words, the shepherd is strongly engaged and acts as a mediator of information flow between stakeholders by assembling experimental, computational and technical backgrounds. In addition to the communication aspect, the shepherd also leads the FAIRification process and is involved at a technical level (development of templates, annotation and curation), while spreading the awareness of the value of FAIR data.
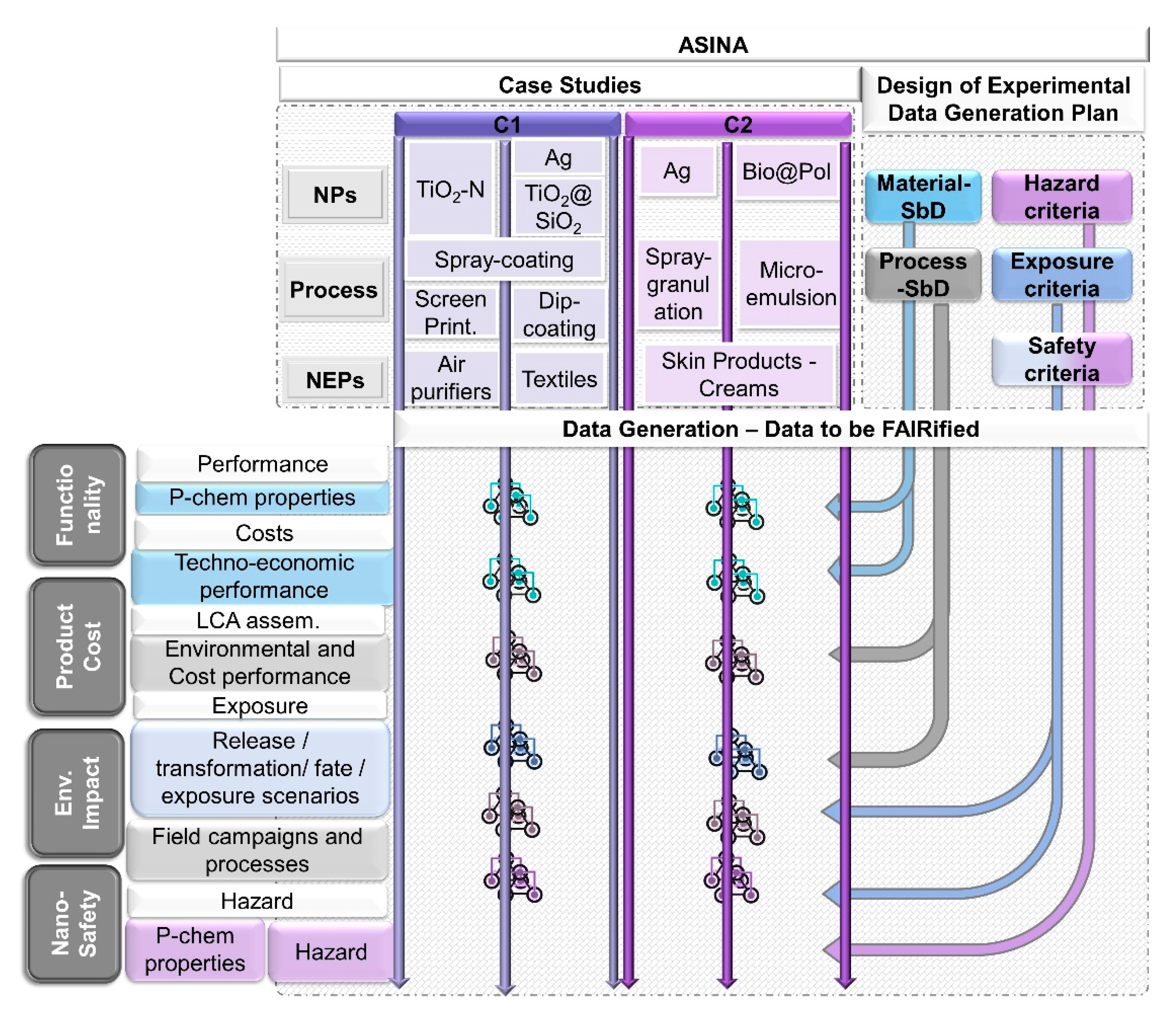
ASINA offers an excellent opportunity to describe how the data shepherd can help to organise complex data from multidisciplinary sources, its capturing, communication among partners, and FAIRification. In a series of articles on the DMP and FAIR data in the ASINA project, the rationale and importance of a defined workflow for curation purposes is described that facilitates the ideation and concretisation of actions and communications among partners.
Traditionally, the building blocks of data management are data templates. In ASINA we chose to create case-specific templates that cover the different aspects of the work to be performed and are able to capture all the necessary metadata to make the data fully understandable. These templates are then annotated and indexed to support human and machine data discovery and understanding. The first step, before any data capturing, is to establish a strong and clear communication with all project partners and acquire the knowledge and information to facilitate the data template design. Figure 1 demonstrates the roadmap for the template creation. A focused effort in each step in the workflow facilitates the identification of critical elements within the step.
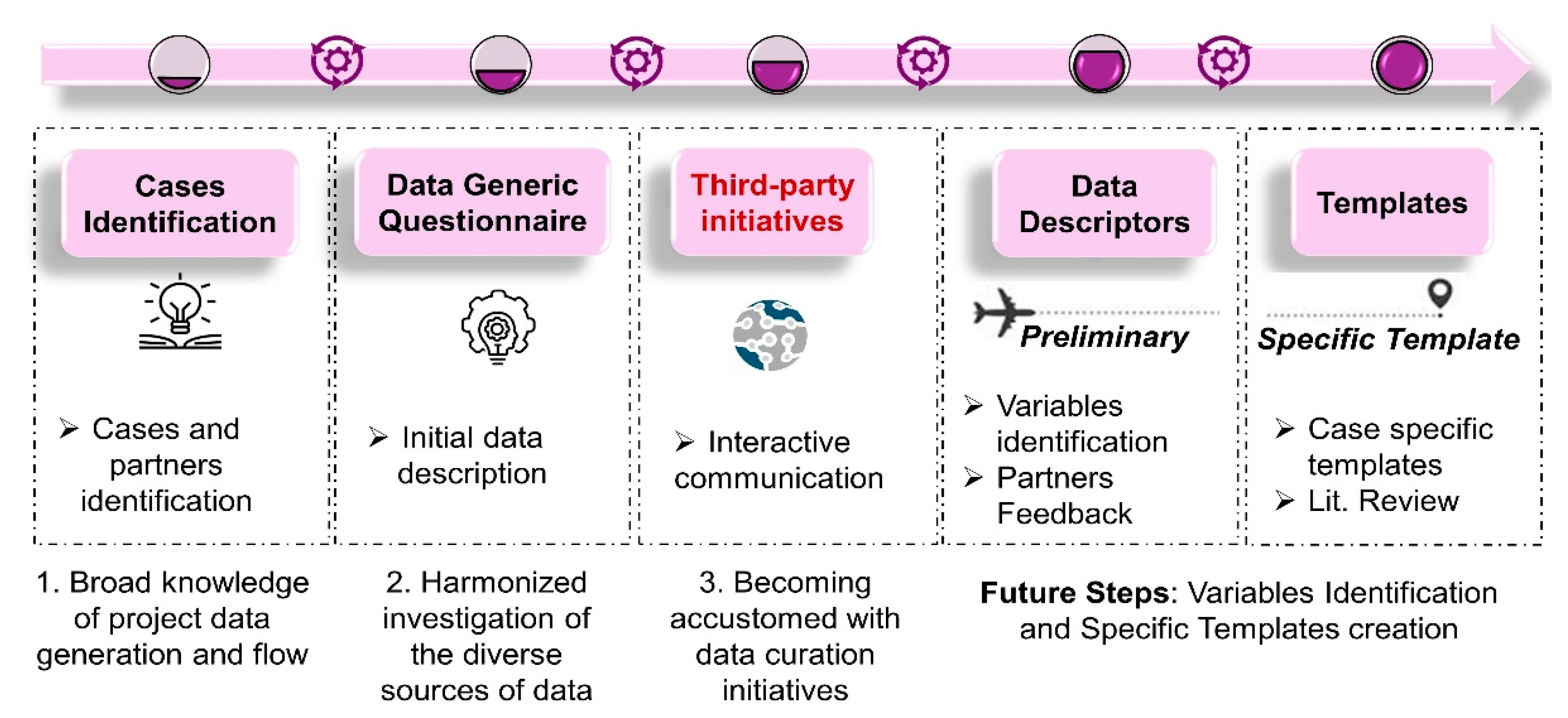 Figure 1. General workflow. Roadmap to final templates creation to be FAIRified for fit-on-purpose-specific cases.
Figure 1. General workflow. Roadmap to final templates creation to be FAIRified for fit-on-purpose-specific cases.
- Initially, project cases to be captured are comprehended and identified, usually from the Grant Agreement and presentations made among the consortia. The relevant data creators and analysts are also identified in this step. A broad knowledge and a holistic visual conceptualization of data to be generated and the flow within is required.
- A questionnaire for an initial data description follows, which is circulated among the relevant partners previously identified. This step allows the data shepherd to gain an additional level of comprehension in the process.
- Next, an interactive communication process is performed among the DMP responsible personnel and, external to the project, FAIR data initiatives. In ASINA’s case, a Transnational Access application with the H2020 e-infrastructure project NanoCommons was initiated.
- The next step includes the identification of data descriptors that define the variables of interest based on the partners’ initial feedback to the questionnaire. The preliminary template is created and circulated among the relevant partners to collect additional feedback regarding the dataset.
- Finally, a detailed exploration of additional variables that “complete” the template is included and shared with the relevant partners.
More details on the steps is available from Furxhi et al., 2021. Note that the final two steps are data-oriented. At previous steps, the content may vary, but the workflow is the same across diverse subjects. It is at those two finals steps that the template design starts to differentiate among project goals and datasets. For this reason, those steps are captured in detail in specific papers for exposure data (Furxhi et al., 2021a) and antimicrobial functionality data (Furxhi et al., 2021b).
References
- Furxhi et al., 2021: Furxhi, I.; Arvanitis, A.; Murphy, F.; Costa, A.; Blosi, M. Data Shepherding in Nanotechnology. The Initiation. Nanomaterials 2021, 11, 1520. https://doi.org/10.3390/nano11061520.
- Furxhi et al., 2021a: Furxhi, I.; Koivisto, A.J.; Murphy, F.; Trabucco, S.; Del Secco, B.; Arvanitis, A. Data Shepherding in Nanotechnology. The Exposure Field Campaign Template. Nanomaterials 2021, 11, 1818. https://doi.org/10.3390/nano11071818.
- Furxhi et al., 2021b: Furxhi, I.; Varesano, A.; Salman, H.; Mirzaei, M.; Battistello, V.; Tomasoni, I.T.; Blosi, M. Data Shepherding in Nanotechnology: An Antimicrobial Functionality Data Capture Template. Coatings 2021, 11, 1486. https://doi.org/10.3390/coatings11121486.
- Papadiamantis et al., 2020: Papadiamantis, A. G.; Klaessig, F. C.; Exner, T. E.; Hofer, S.; Hofstaetter, N.; Himly, M.; Williams, M. A.; Doganis, P.; Hoover, M. D.; Afantitis, A.; Melagraki, G.; Nolan, T. S.; Rumble, J.; Maier, D.; Lynch, I. Metadata Stewardship in Nanosafety Research: Community-Driven Organisation of Metadata Schemas to Support FAIR Nanoscience Data. Nanomaterials 2020, 10 (10), 2033. https://doi.org/10.3390/nano10102033.