Data completeness, minimum information checklist, data quality
We present here multiple sets of definitions of these terms. These build all alternatives since there are no globally accepted definitions yet. However, we are not just presenting them in a chronological order but according to a subjective ranking. This doesn’t exclude that the definitions lower down present specific aspects better than earlier definitions or are better applicable in specific or more general situations.
This is a very active area and it is hard to keep up-to-date. Therefore, please help us to identify important developments by editing the mural below. We will then transfer this information into additional Handbook pages.
FAIRness and quality scores You might also be interested in approaches to score the completeness, quality and FAIRness of datasets.
Shorter and more focused definitions: (compared to further down)
Based on: Marchese Robinson et al., 2016
© 2016 by the authors
In the recommendations given by Marchese Robinson et al., shorter definitions than the original concepts presented in the same paper were proposed to the community for the sake of clarity:
- Data completeness
- This is a measure of the extent to which the data and metadata which serve to address a specific need are, in principle, available.
- Data quality
- This is a measure of the degree to which a single datum or finding is clear and the extent to which it, and its associated metadata, can be considered correct.
The quality and completeness of (curated) nanomaterial data are viewed as overlapping, yet distinct, concepts.
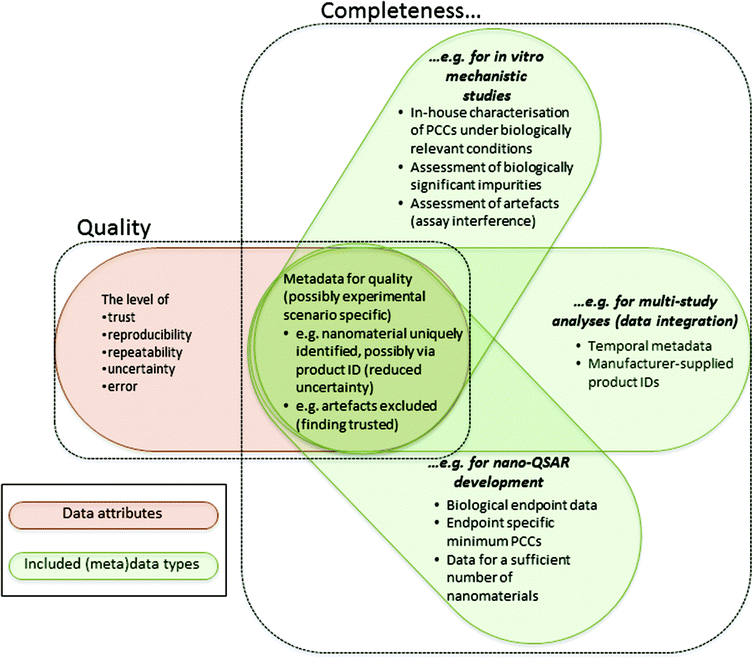
The figure illustrates various contexts, meaning the experimental scenario and intended use of the data, and the kinds of (meta)data which may be required to assess those data as being sufficiently complete and of acceptable quality.
- PCCs is an abbreviation for physicochemical characteristics.
- The concept of data completeness applies to a set of data and their associated metadata. Hence, the number of data points of a specific kind (e.g. number of nanomaterials screened in a cytotoxicity assay) may be a completeness criterion in specific contexts if a given number of data points are required to achieve a specific aim.
- In contrast, the concept of data quality applies to a single datum (i.e. a single data point) or a single “finding”, taking into account its associated metadata. A “finding” might be a conclusion derived from analysis of a set of raw or processed data and the “metadata” associated with that finding might include these data.
- The dependence of both completeness and quality upon metadata is not entirely for the same reasons. For example, metadata (e.g. related to the nanomaterial identity and experimental conditions) are required to determine the relevance of the data for answering a specific question. The relevance of data for answering a specific question affects the completeness of the data, since only relevant data should be counted when evaluating completeness, but not the quality of a datum or finding. In addition, metadata are required to make the meaning of the datum or finding clear, reducing uncertainty in a qualitative sense and facilitating reproducibility, and to assess the level of trust, reproducibility, repeatability, uncertainty and error. All of these issues affect the quality of a datum or finding. However, the quality of a datum or finding does not directly affect the completeness of the data.
- The context determines the (meta)data required for completeness. Whilst quality is not dependent upon the intended use of the data, the specific (meta)data required for quality assessment may be dependent upon the experimental scenario. For example, specific kinds of (meta)data will be required in specific in vitro studies to assess assay interference and, hence, assess the error in a given datum.
- The examples in this figure are by no means exhaustive or, necessarily, minimum requirements. The example contexts and their requirements are not necessarily mutually exclusive. For example, a nano-QSAR might be developed via integrating data across multiple in vitro mechanistic studies.
- Where examples are provided in this figure of specific metadata which might be required for data completeness in different contexts, it should be recalled that the availability of these metadata could also affect the quality of individual data points or findings.
More detailed explanations to these terminology recommendations can be found in Section S4 of the supporting information of the paper cited above. Main points are:
- Relevance of the data for answering a specific question is related to data completeness.
- In contrast, data quality should not be considered a function of the purpose for which the data are used.
- A finding might be a conclusion derived from analysis of a set of raw or processed data and the “metadata” associated with that finding might include these data.
- “In principle” means that the metadata can still be of insufficient quality. Completeness only evaluates if it is there or not.
- Quality is associated with a specific datum or finding. Datasets, in which all data is of high quality, can be loosely labeled as “high quality datasets”.
- Format compliance of a dataset is not considered a data quality issue.
Broad and flexible definitions employed for reviewing prior work
Based on: Marchese Robinson et al., 2016 and references therein.
© 2016 by the authors
The original set of definitions, all the previous definitions are in some way or another derived from, is taken from Marchese Robinson et al.
- Key concept 1 - Data completeness
- The completeness of data and associated metadata may be considered a measure of the availability of the necessary, non-redundant (meta)data for a given entity e.g. a nanomaterial or a set of nanomaterials in the context of nanoscience. However, there is no definitive consensus regarding exactly how data completeness should be defined in the nanoscience, or wider scientific, community. Indeed, metadata availability may be considered an issue distinct from data completeness.
Data completeness may be considered to include, amongst other kinds of data and metadata, the extent of nanomaterial characterisation, both physicochemical and biological, under a specified set of experimental conditions and time points. It may also encompass the degree to which experimental details are described, as well as the availability of raw data, processed data, or derived data from the assays used for nanomaterial characterisation. Data completeness may be considered to be highly dependent upon both the questions posed of the data and the kinds of data, nanomaterials and applications being considered. Data completeness may be defined in terms of the degree of compliance with a minimum information checklist (Table 2). However, when estimating the degree of data completeness, it should be recognised that this will not necessarily be based upon consideration of all independent variables which determine, say, a given result obtained from a particular biological assay. This is especially the case when data completeness is assessed with respect to a predefined minimum information checklist (Table 2). Precise definitions of completeness may evolve in tandem with scientific understanding. - Key concept 2 - Minimum information checklist
- Minimum information checklists might otherwise be referred to as minimum information standards, minimum information criteria, minimum information guidelines or data reporting guidelines etc. These checklists define a set of data and metadata which “should” be reported – if available – by experimentalists and/or captured during data curation. Again, the precise set of data and metadata which “should” be reported may be considered to be highly dependent upon both the questions posed of the data and the kinds of data, nanomaterials and applications being considered. There are two possible interpretations of the purpose of these checklists: (1) they should be used to support assessment of data completeness (Key concept 1); (2) data should be considered unacceptable if they are not 100% compliant with the checklist.
- Key concept 3 - Data quality
- Data quality may be considered a measure of the potential usefulness, clarity, correctness and trustworthiness of data and datasets. However, there is no definitive consensus regarding exactly how data quality should be defined in the nanoscience, or wider scientific, community.
Data quality may be considered dependent upon the degree to which the meaning of the data is “clear” and the extent to which the data are “plausible”. In turn, this may be considered to incorporate (aspects of) data completeness (Table 1). For example, data quality may be considered to be (partly) dependent upon the “reproducibility” of data and the extent to which data are reproducible and their reproducibility can be assessed will partly depend upon the degree of data completeness in terms of the, readily accessible, available metadata and raw data. As well as “reproducibility”, data quality may be considered to incorporate a variety of related issues. These issues include systematic and random “errors” in the data, data “precision” (which may be considered related to notions such as “repeatability” or “within-laboratory reproducibility”), “accuracy” and “uncertainty”. (As indicated by the cited references, different scientists may provide somewhat different definitions for these concepts. These concepts may be considered in a qualitative or quantitative sense.) Data quality may also be considered to be dependent upon the “relevance” of the data for answering a specific question, although data “relevance” might be considered an entirely distinct issue from data quality. In the context of data curation, not only the quality of the original experimental data needs to be considered but also quality considerations associated with curated data. Quality considerations associated with curation include the probability of transcription errors and possibly whether a given dataset, structured according to some standardised format (e.g. XML based), was compliant with the rules of the applicable standardised format (e.g. as documented via an XML schema). Such compliance, amongst other possible aspects of data quality, could be determined using validation software.
References
- Marchese Robinson et al., 2016: Marchese Robinson, R. L.; Lynch, I.; Peijnenburg, W.; Rumble, J.; Klaessig, F.; Marquardt, C.; Rauscher, H.; Puzyn, T.; Purian, R.; Åberg, C.; Karcher, S.; Vriens, H.; Hoet, P.; Hoover, M. D.; Hendren, C. O.; Harper, S. L. How Should the Completeness and Quality of Curated Nanomaterial Data Be Evaluated? Nanoscale 2016, 8 (19), 9919–9943. https://doi.org/10.1039/C5NR08944A.